From Allen Institute for Artificial Intelligence and Microsoft Research.
Authors: Antoine Bosselut, Hannah Rashkin, Maarten Sap, Chaitanya Malaviya, Asli Celikyilmaz, Yejin Choi
Title: COMET: Commonsense Transformers for Automatic Knowledge Graph Construction
In: ACL, 2019.
Introduction
本文是Allen实验室发表在ACL2019的一篇关于自动常识知识库构建的文章。作者提出了Commonsense Transformers(COMET)生成模型,主体框架是Transformer语言模型,在ATOMIC和ConceptNet知识库中选取种子知识训练集进行预训练,使得模型可以自动构建常识知识库。Allen实验室也提供了Demo和Code,Demo挺有意思的,输入一个event(有参与者),就可以返回一个常识知识图。
COMET与许多使用规范模板存储知识的传统知识库相反,常识知识库仅存储松散结构的开放式知识描述。实验结果表明,COMET能够产生新的人类评价为高质量的知识,高达77.5%(ATOMIC)和91.7%(ConceptNet)精度。使用常识生成模型COMET进行自动构建常识知识库,也许就会成为知识抽取构建知识库的合理替代方案。
Motivation
在阅读文本时,人类会做出常识性的推理,这些推理对理解叙事性故事(narrative,由具有逻辑、因果等关系的events构成)起支撑作用。想要让机器和人类一样具有这个能力,必须可以无限地获取相关常识,如果获得准确的常识更好。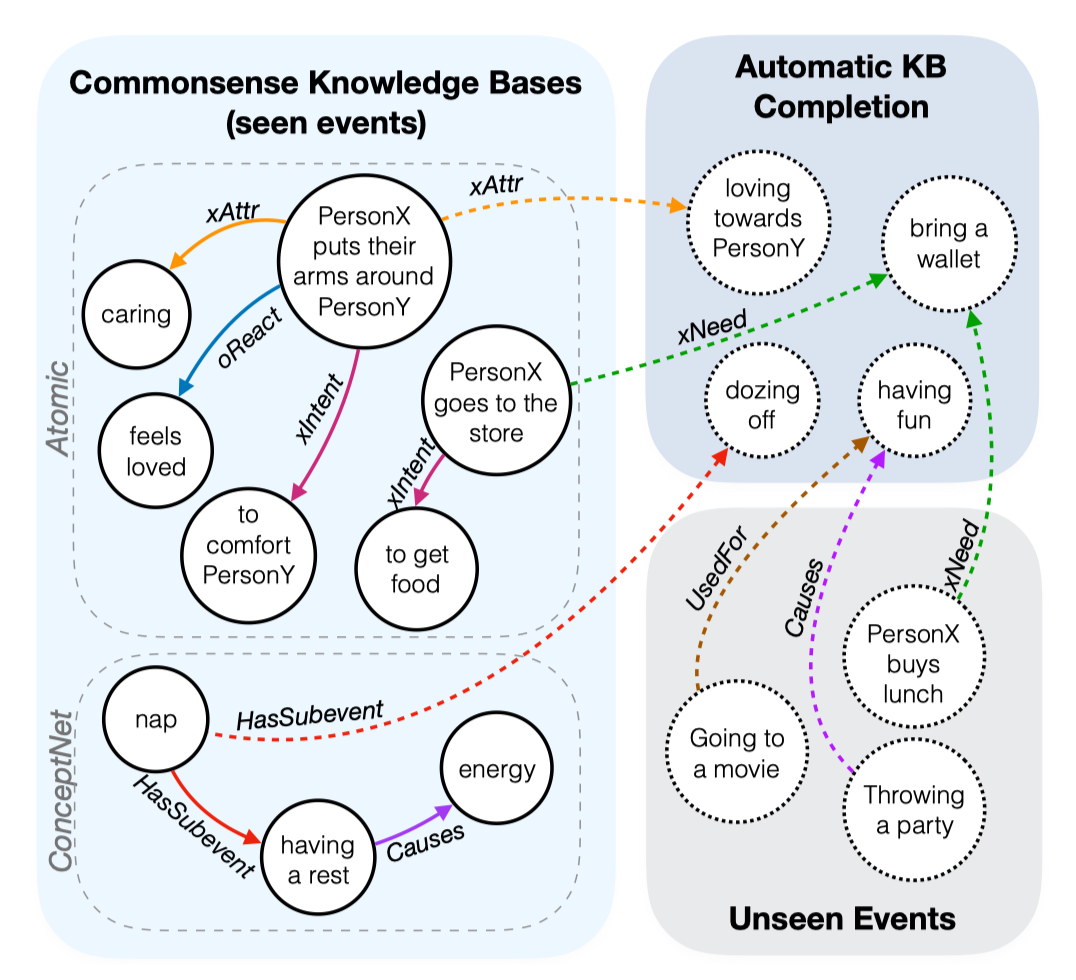
针对问题:
- 之前大部分自动知识库构建的工作针对的是百科知识,百科知识的特点是实体和关系之间很好建模,关系是比较明确的。但是常识知识不一样,实体间的关系是难以确定的,这就导致现有工作实效。
- 华盛顿大学的OpenIE通过抽取开放文本中的实体和关系,构建知识库。对于常识知识来说,有一定比例是隐含知识,换言之就是两跳的知识。
解决方案:
借鉴Transformer上下文感知语言模型,在ATOMIC和ConceptNet知识库中选取种子知识训练集进行预训练,使得模型可以自动构建常识知识库,给定头实体和关系,生成尾实体。
Model
任务定义
训练样例${s, r, o}$,s是三元组的头实体,r是实体间的关系,o是尾实体。
例如ConceptNet中:(s=“take a nap”, r=Causes, o=“have energy”)。
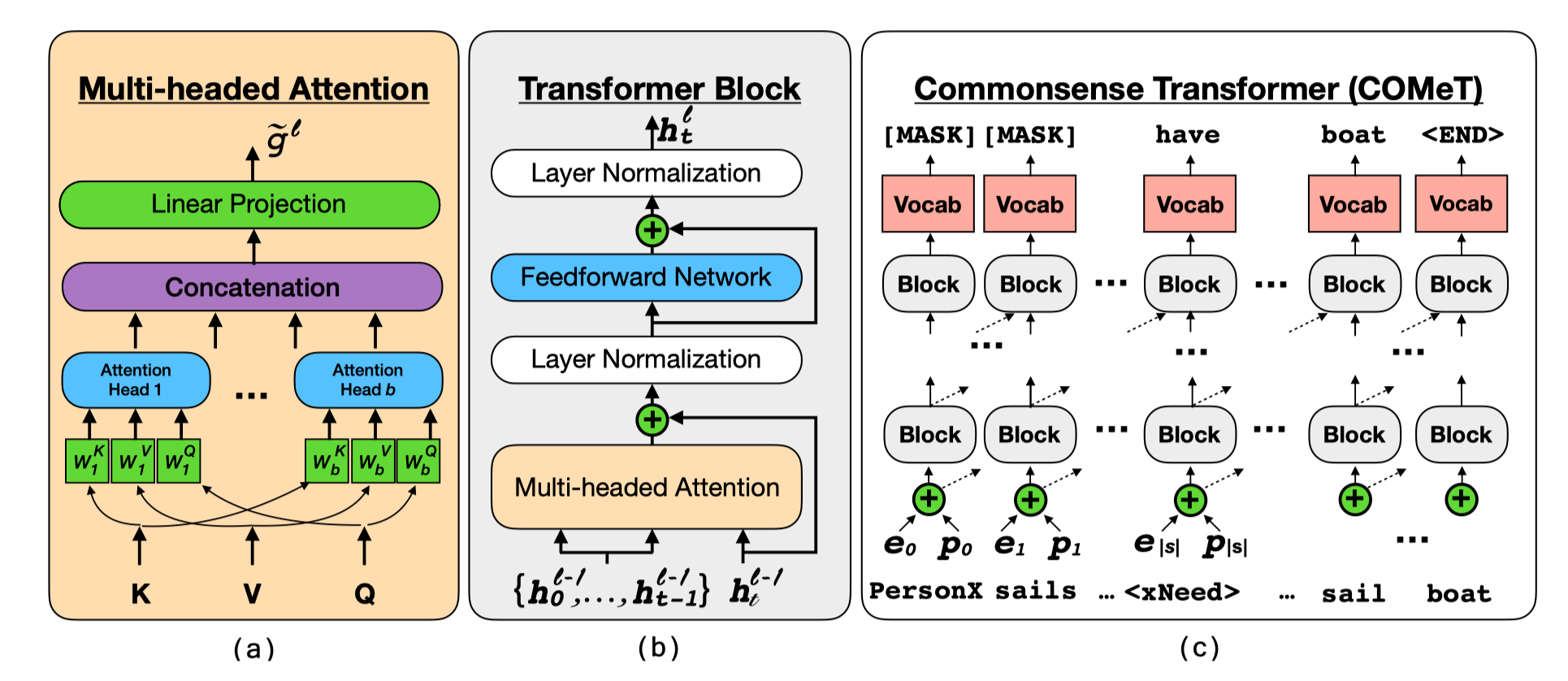
模型基于GPT生成式Transformer语言模型,这个模型的细节就不多说了,说说COMET的实现细节,确实在模型上没啥创新的东西,就是在用语言模型做尾实体的生成。
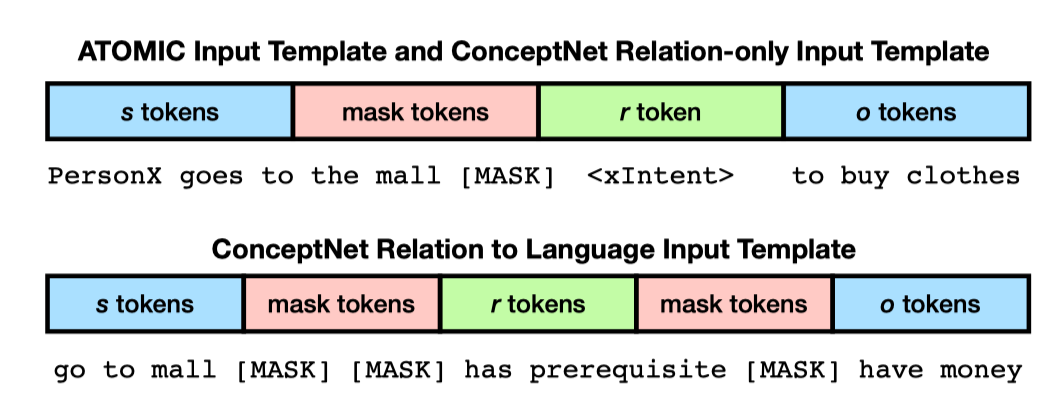
喂给GPT的输入需要做一些改动,如下图所示,对于ATOMIC和ConceptNet中两个实体间只有一个关系的,r和o之间就不需要[MASK]符号,ConceptNet中存在很多s和o之间有多个关系的情况,此时需要再加[MASK]加以区分。
Implementation
目标函数为:
用ATOMIC和ConceptNet作为种子知识库预训练GPT,GPT的参数设置与OpenAI的类似,ATOMIC的学习率设置的6.25e-5,ConceptNet设置的1e-5。
Experiment
ATOMIC
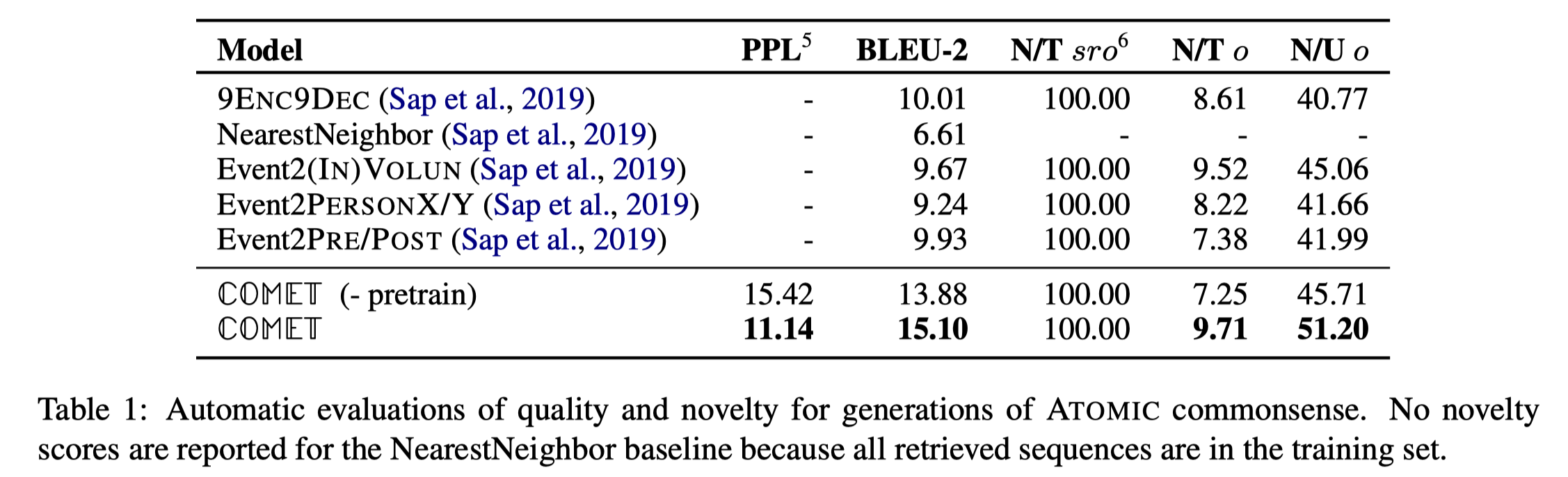
实验一的评价指标分别是:PPL(语言模型的)、BLEU-2(文本生成的)、N/Tsro(新三元组/所有三元组)、N/To(新三元组中,新尾实体/所有的独立尾实体)和N/Uo(新尾实体/所有的独立尾实体):
实验二选了9个关系做了人工评测,指标是尾实体生成合理的比例。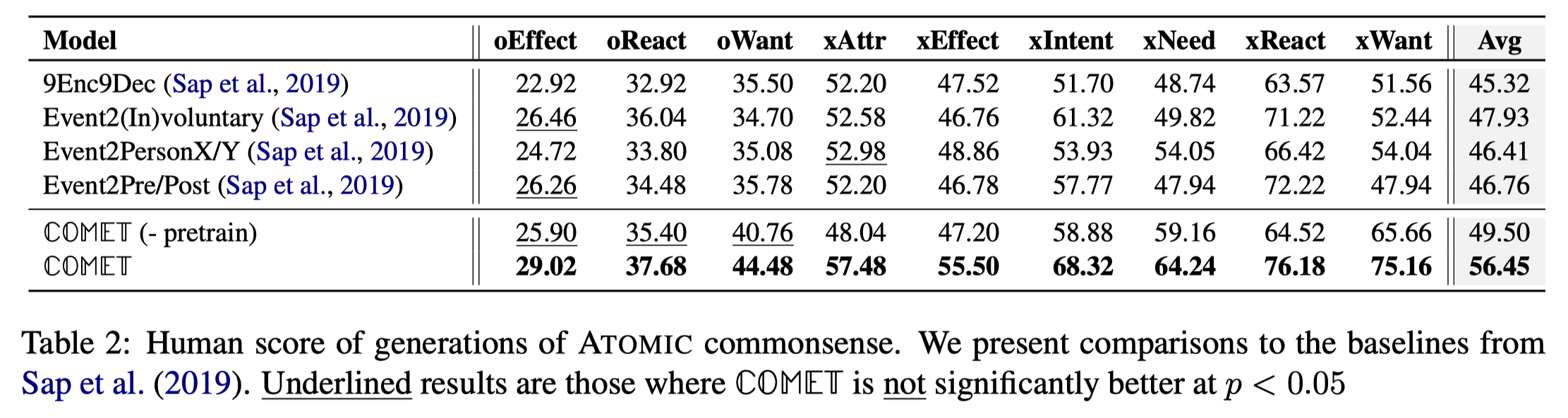
以上两个实验也验证了预训练同样在这个任务上有效。
论文还给出了一些解码阶段的策略,最后验证beam search在xAttr、xEffect关系上效果较好,其他的关系greedy decoding效果好一些: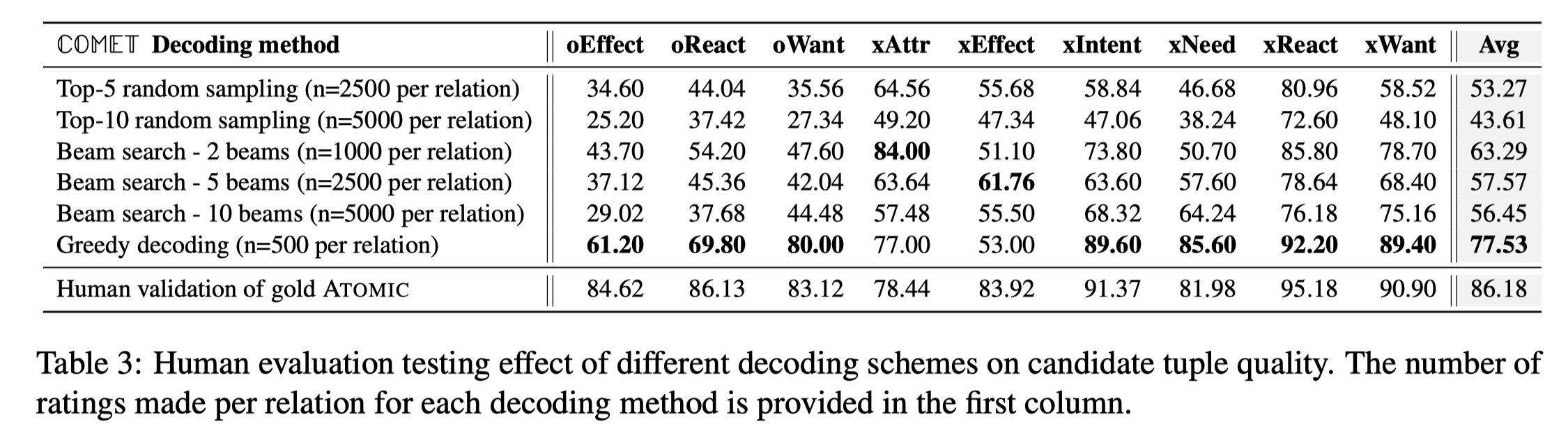
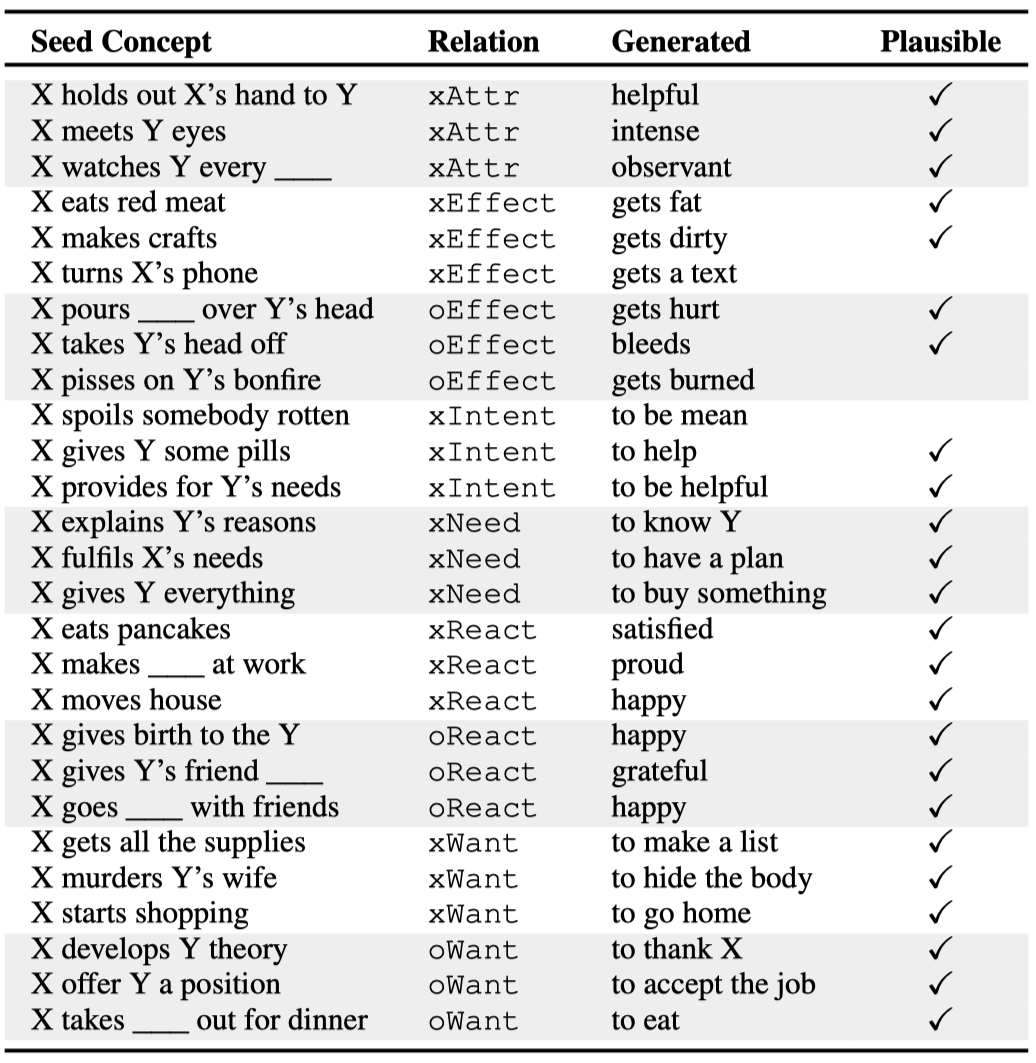
人工评测举例:
ConceptNet
在ConceptNet上人工测评很高,PPL也很低:
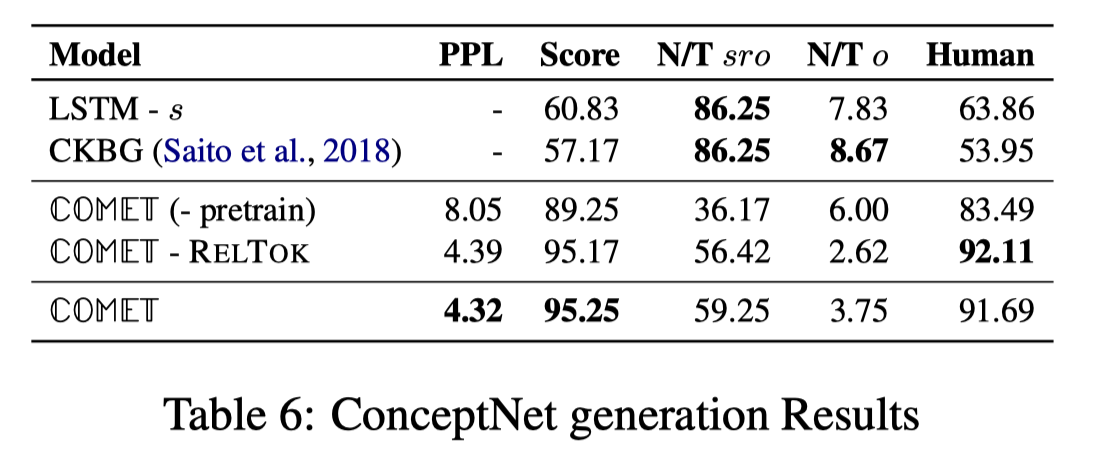
人工评测举例:
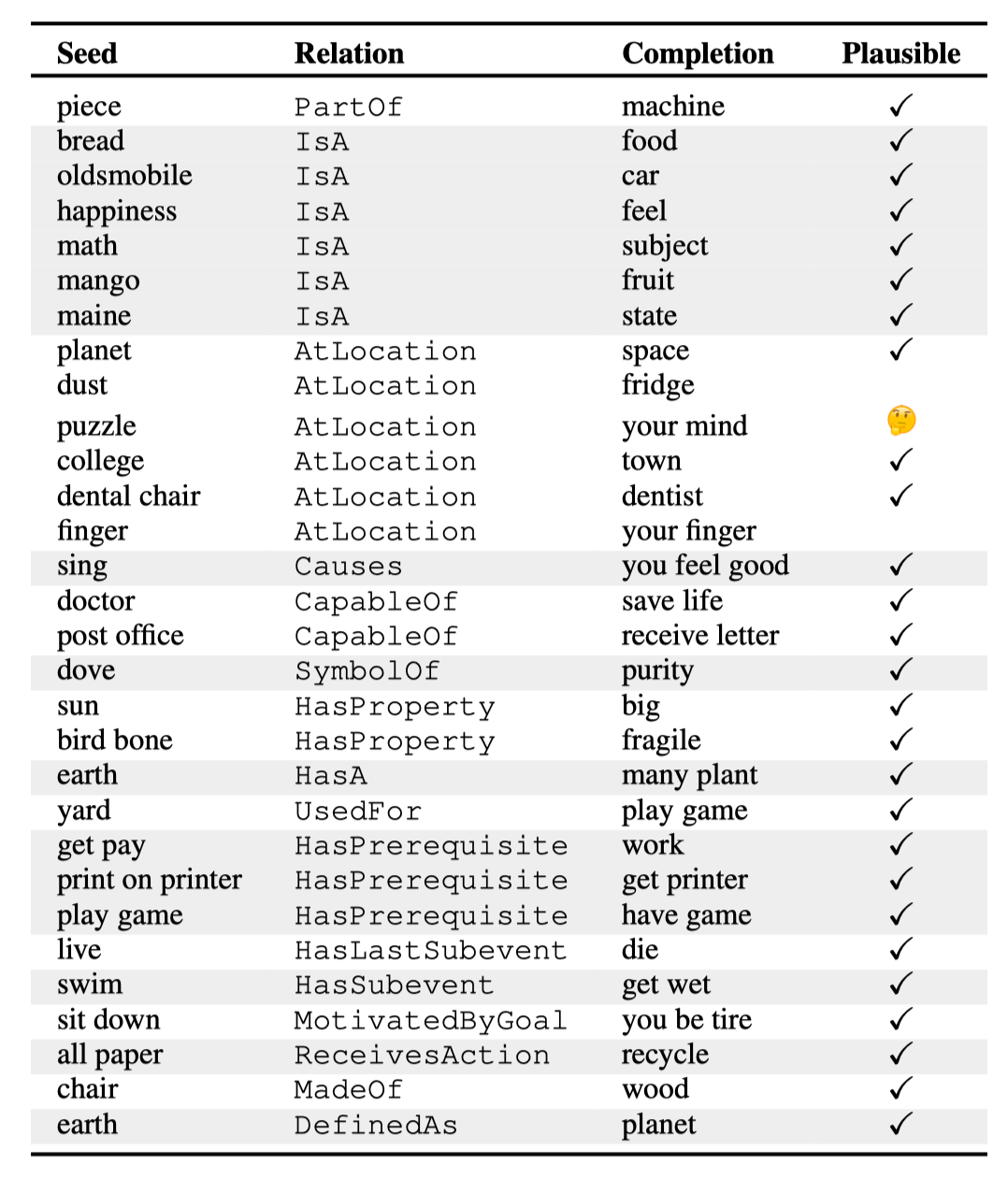
Conclusion
COMET是自动常识知识库是一次尝试,也挺成功的,基于GPT,用ATOMIC和ConceptNet预训练。Transformer真是个强大的编码器,预训练也是个好东西。