From Google Brain and CMU.
Authors: Zihang Dai∗, Zhilin Yang∗, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov
Title: TransformerXL: Attentive Language Models Beyond a Fixed-Length Context.
In: ACL, 2019
Introduction
为了帮助理解XLNet[4],本文对其核心框架Transformer-XL作一个解读。本文发表在ACL2019上,论文想要解决的问题:如何赋予编码器捕获长距离依赖的能力。目前在自然语言处理领域,Transformer的编码能力超越了RNN,但是对长距离依赖的建模能力仍然不足。在基于LSTM的模型中,为了建模长距离依赖,提出了门控机制和梯度裁剪,目前可以编码的最长距离在200左右。在基于Transformer的模型中,允许词之间直接self-attention,能够更好地捕获长期依赖关系,但是还是有限制。
Motivation
Transformer编码固定长度的上下文,即将一个长的文本序列截断为几百个字符的固定长度片段(segment),然后分别编码每个片段[1],片段之间没有任何的信息交互。比如BERT,序列长度的极限一般在512。动机总结如下:
- Transformer无法建模超过固定长度的依赖关系,对长文本编码效果差。
- Transformer把要处理的文本分割成等长的片段,通常不考虑句子(语义)边界,导致上下文碎片化(context fragmentation)。通俗来讲,一个完整的句子在分割后,一半在前面的片段,一半在后面的片段。
文章围绕建模长距离依赖,提出Transformer-XL【XL是extra long的意思】:
- 提出片段级递归机制(segment-level recurrence mechanism),引入一个记忆(memory)模块(类似于cache或cell),循环用来建模片段之间的联系。
- 使得长距离依赖的建模成为可能;
- 使得片段之间产生交互,解决上下文碎片化问题。
- 提出相对位置编码机制(relative position embedding scheme),代替绝对位置编码。
- 在memory的循环计算过程中,避免时序混淆【见model部分】,位置编码可重用。
小结一下,片段级递归机制为了解决编码长距离依赖和上下文碎片化,相对位置编码机制为了实现片段级递归机制而提出,解决可能出现的时序混淆问题。
Model
Vanilla Transformer
普通的Transformer是如何编码的?[2]给了动图,很形象,每个segment分别编码,相互之间不产生任何交互。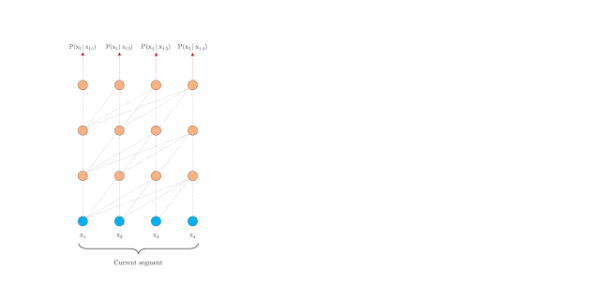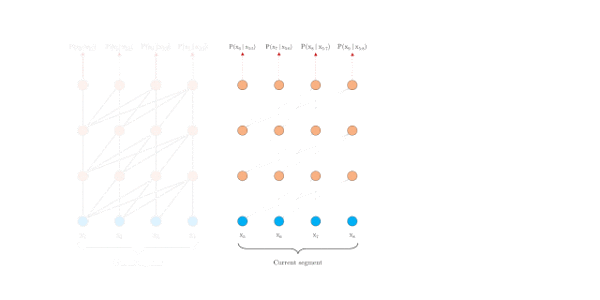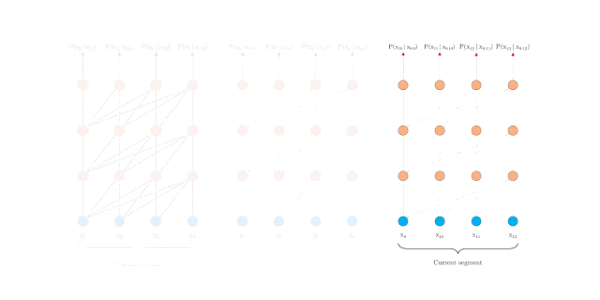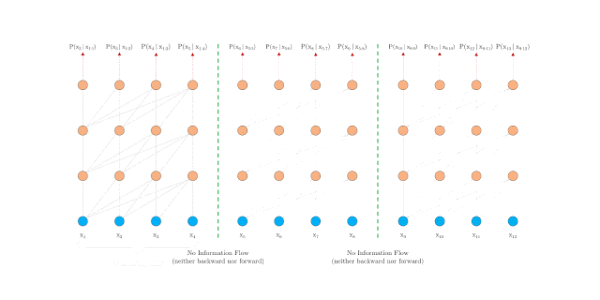
segment-level recurrence mechanism
公式显示不了,请跳转至:https://zhuanlan.zhihu.com/p/70745925
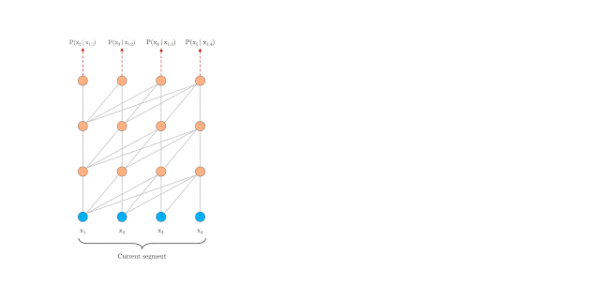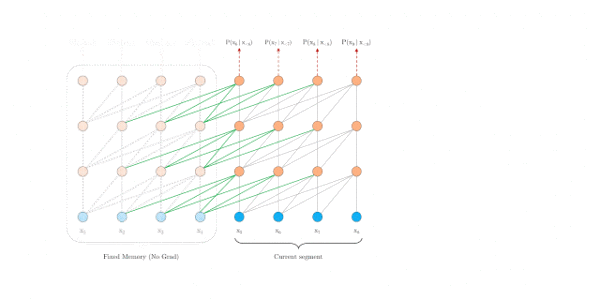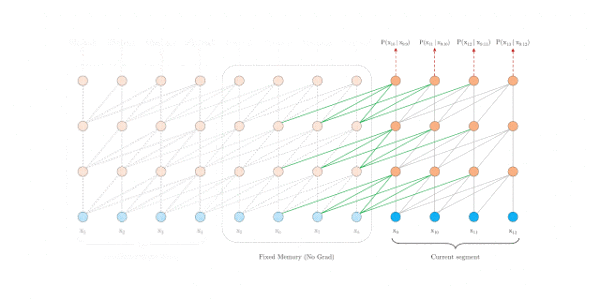
relative position embedding scheme
公式显示不了,请跳转至:https://zhuanlan.zhihu.com/p/70745925
faster evaluation
在评估时, Transformer-XL比Vanilla Transformer具有更长的有效上下文,并且Transformer-XL能够在不需要重新计算的情况下处理新段中的所有元素,显著提高了速度。下图是评估阶段的对比图:
Vanilla Transformer
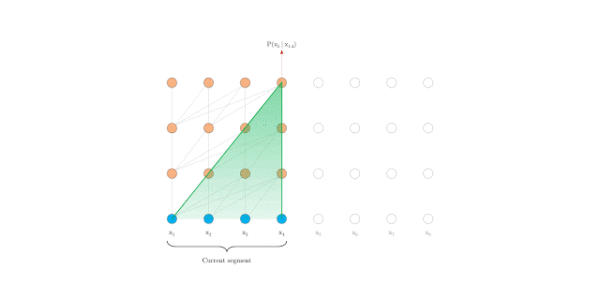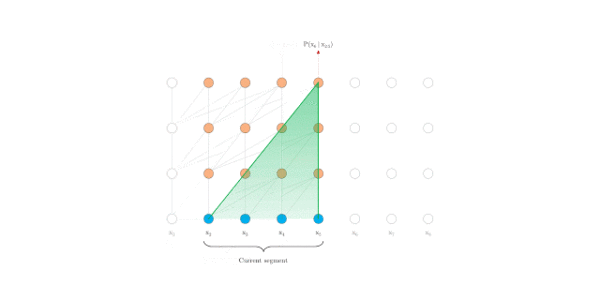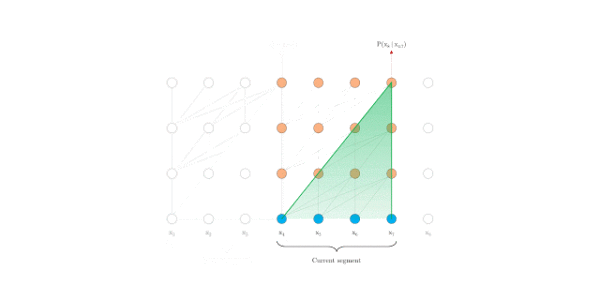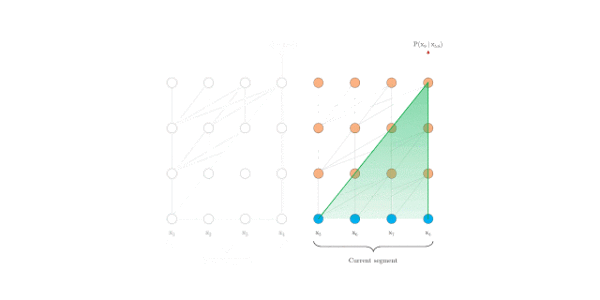
Transformer-XL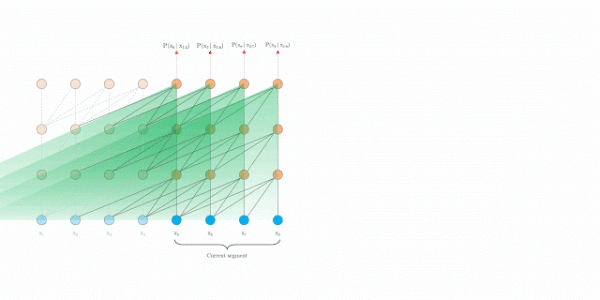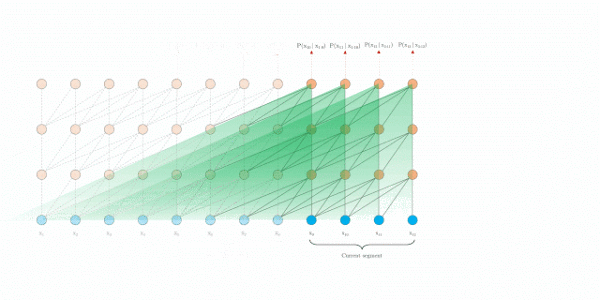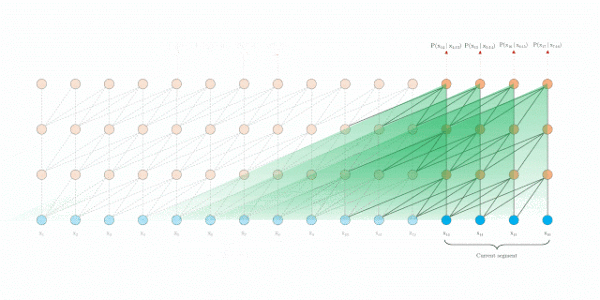
Experiment
实验部分是对基于Transformer-XL的语言模型进行评估,分为字符级和词级。评价指标分别是bpc(每字符位数)和PPL(困惑度),越小越好。enwiki8和text8用的是bpc。Transformer-XL在多个语言模型基准测试中实现了最先进的结果。 Transformer-XL也是第一个在char级语言模型基准enwiki8上突破1.0。

去除实验:
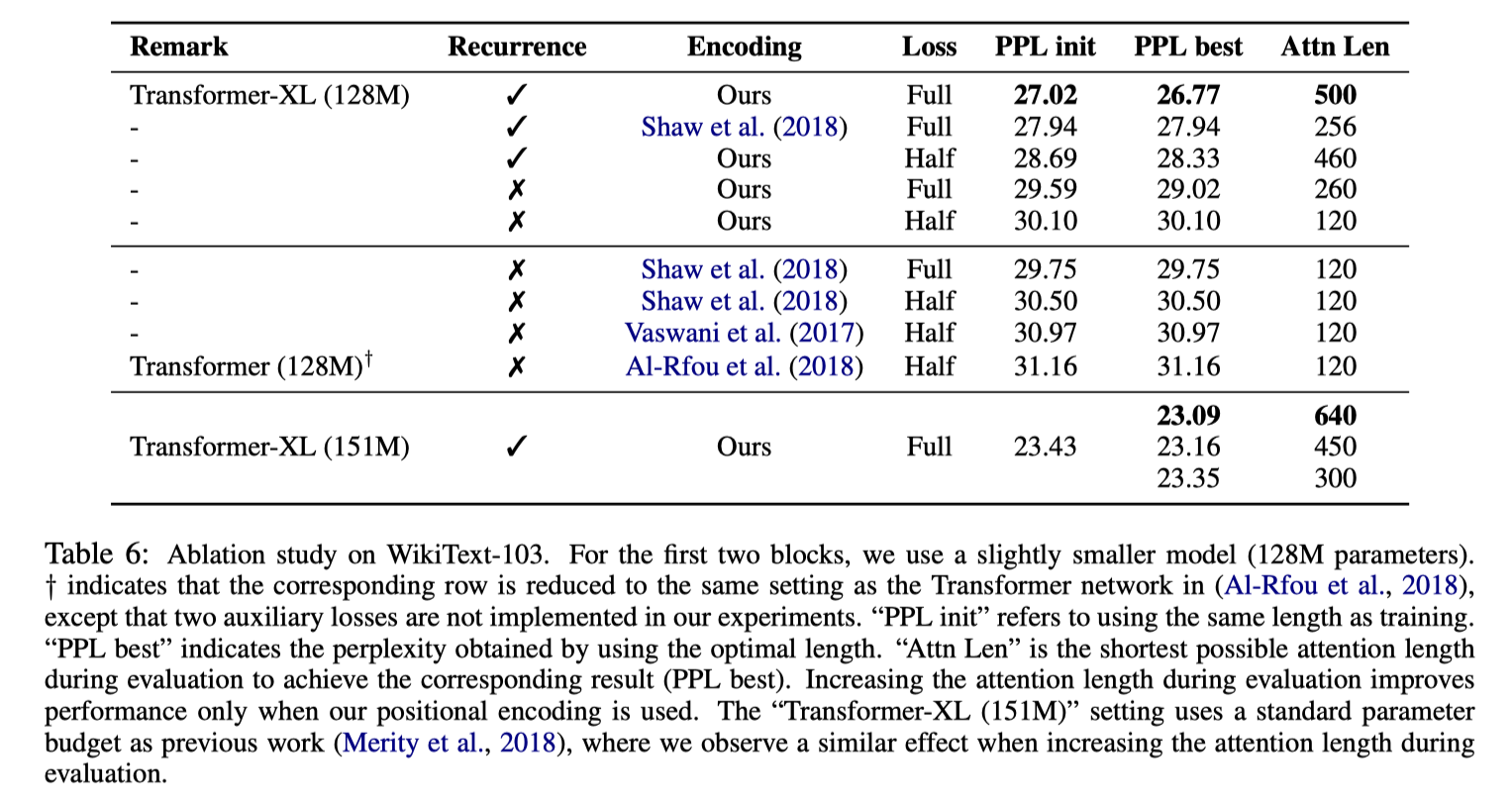
重点是本文设计的相对位置编码优于其他工作,memory的设计也有很大的提升。
补充材料中Transformer-XL生成的文本也比较有意思,感兴趣可以去跳转page 17 in [1]。
最后,Transformer-XL在评估阶段的速度也明显快于 vanilla Transformer,特别是对于较长的上下文。例如,对于 800 个字符的上下文长度,Transformer-XL 比 vanilla Transformer 快 363 倍;而对于 3800 字符的上下文,Transformer-XL 快了 1874 倍。
Conclusion
Transformer-XL从提高语言模型的长距离依赖建模能力出发,提出了片段级递归机制,设计了更好的相对位置编码机制,对长文本的编码更有效。不仅如此,在评估阶段速度更快,很巧妙。在此基础上,XLNet[4]从无监督预训练方法出发,对比自回归语言模型和自编码语言模型的优缺点,设计出了排队语言模型,在自然语言处理下游任务中大放异彩。预训练语言模型属于自监督学习的范畴,这两篇论文从语言模型的根本问题出发(建模长距离依赖/更好地编码上下文),提出一个主要方法(片段级递归机制/排列语言模型),在实现过程中发现需要重新设计子模块(相对位置编码/双流注意力机制),最后完成significant work,使得设计的任务很有说服力,理论性强。
Reference
[1]. Zihang Dai, Zhilin Yang, Yiming Yang, William W Cohen, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019.
[2]. 机器之心报道. https://zhuanlan.zhihu.com/p/56027916.
[3]. 官方代码. https://github.com/kimiyoung/transformer-xl.
[4]. Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov and Quoc V. Le. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv preprint arXiv:1906.08237, 2019.