Introduction
本文出自韩国 Naver Corporation 和 Seoul National University ,工作定义在句子匹配任务上。Sentence Matching的关键之处在于如何表示句子语义(目前感觉就是上下文信息和类似 POS 的特征信息,不能说是语义),如何理解句子之间的语义关系。查看相关工作可以得到,Attention 算法在刻画两个句子语义关系和对齐句子成分方面有很好的效果,但是也有不足之处。Attention 机制仅使用求和操作,这样来自于上层的特征信息就会被破坏,不能完整保留下来。作者借鉴了图像识别中的DenseNet的密集连接操作,旨在更好地利用原始特征信息。
本文提出Densely-connected co-attentive RNN,密集连接stack RNN,这样从最底层到最顶层一直保留原始信息,在stack RNN的每一个block中,用co-attention的方式得到两个句子之间的交互信息,能量函数用的最简单的算cos距离。因为stack RNN会参数量会迅速增加,影响模型训练,因此用自编码器进行压缩表示。
模型目前在SNLI的排名第一,集成之后,在测试集上破了90%正确率的大关。过去应该也没有人认为句子匹配任务需要把网络做深,当然现在也是,效果没提升多少,我感觉这只是个尝试,企业就喜欢这种简单粗暴不考虑计算力的模型。
Model
下面对模型详细介绍:模型整体不复杂,但是我不理解的就是自编码器选择的位置和层数为什么是5,文中也没有指出来,也没有实验。
overview
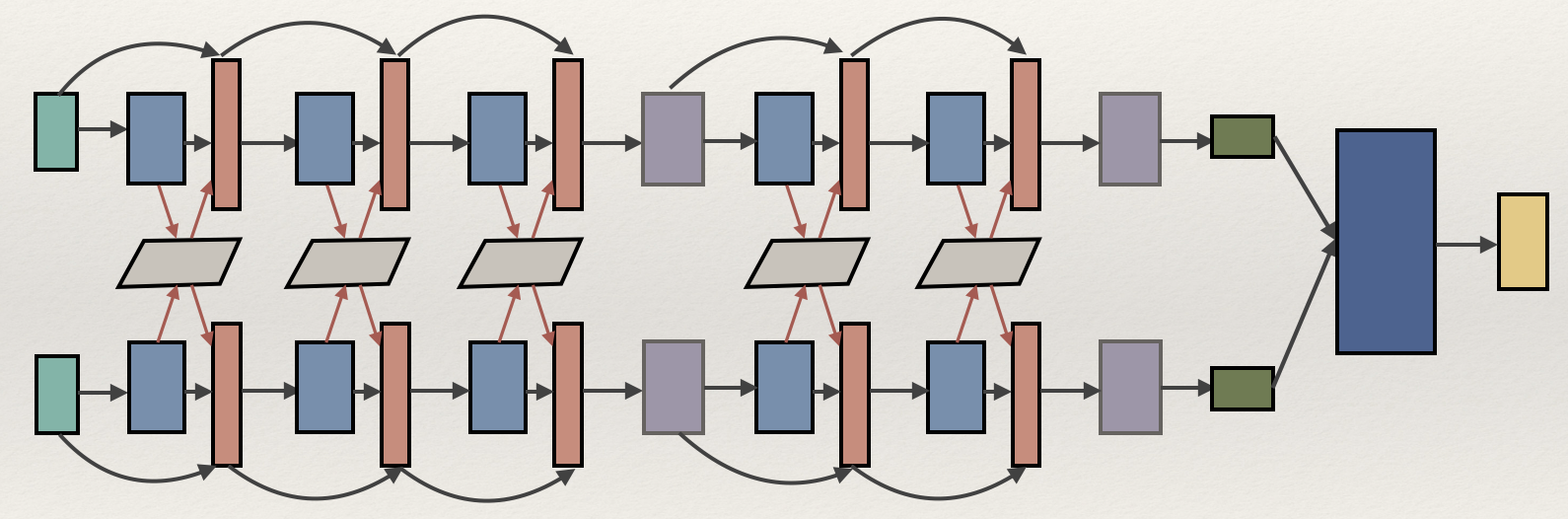
由上图可以看出,整个模型的输入输出,从左到右。
- 最左边的浅绿色是对前提和假设的Embedding;
- 之后过5层的Stack RNN ,中间部分是如何运算的?有哪些参数?灰色块为什么只有两个?这些问题在下一张图详细介绍;
- 在Stack RNN之后是分别对前提和假设进行pooling,映射到同一个维度,得到两者的new representation;
- 蓝色块的作用是对前提和假设做并、相加和相减等运算,一定程度上得到它们之间的距离和相似程度;
- 黄色块是最终的输出,与蓝色块之间是全连接。
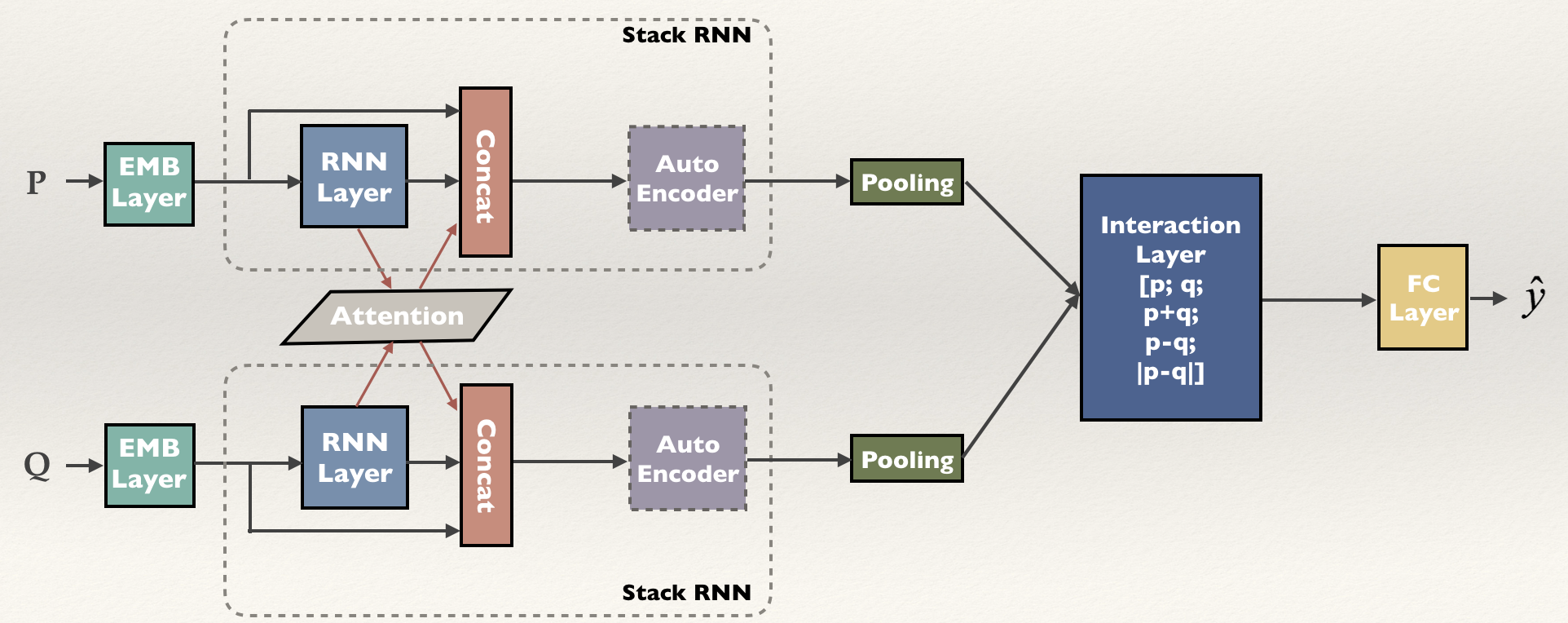
Details in model
Embedding Layer
词向量的特征包括四项:
- 与模型一起训练的Glove词向量: $e^{tr}_{p_i}=E^{tr}(p_i)$;
- 直接拿来用的,保持不变的Glove词向量: $e^{fix}_{p_i}=E^{fix}(p_i)$;
- 用CNN得到的字向量: $c_{p_i}=CharConv(p_i)$;
- Match Flag特征:这是一个0/1特征,表示该词是否在另一句话中出现。
最终的表示是四部分串在一起: 。
Densely connected recurrent Co-attentive networks
这部分非常重要,也就是图Overview中的虚线部分。
蓝色的RNN分别得到前提的表示$h_p$和假设的表示$h_q$,然后就是计算Attention:
- 能量函数e选用的暴力的cos函数: ;
- 然后做soft Max得到注意力权重$\alpha$ : ;
- 得到权重化之后的表示。
在得到a之后,作者并没有像之前的工作一样相加。而是部分借鉴了DenseNet的思想,将本层输入保留,与h , a做concat[这部分并不像图像识别的DenseNet,把每层之间都做了连接,所以并没有保留原始的输出]。
下面是三种得到Stack RNN隐层状态的方式:
- —RNN
- —ResNet
- —DenseNet
最终作者的结合方式是这样:$x^l_t=[h^{l-1}_t;a^{l-1}_t;x^{l-1}_t]$,权重化表示a直接作为特征串在了中间。
AutoEncoder
Stack RNN 这样的结构必然会带来参数急速增长的问题,为了解决这个问题,作者使用了AutoEncoder,但是并没有指出用哪种自编码器和为什么只用2次,实验中也没有指明。但是,自编码器无疑是可以减少参数量,在损失尽量小的情况下压缩参数。
Pooling Layer
这部分没啥,Max Pooling得到维度相同的P、Q表示。
Interaction Layer
最后对P、Q的表示做拼接、相加、相减、绝对值的运算,表示句子之间的匹配:$v=[p;q;p+q,p-q,|p-q|]$ ,然后全连接和soft Max得到P、Q之间的关系。
Experiments
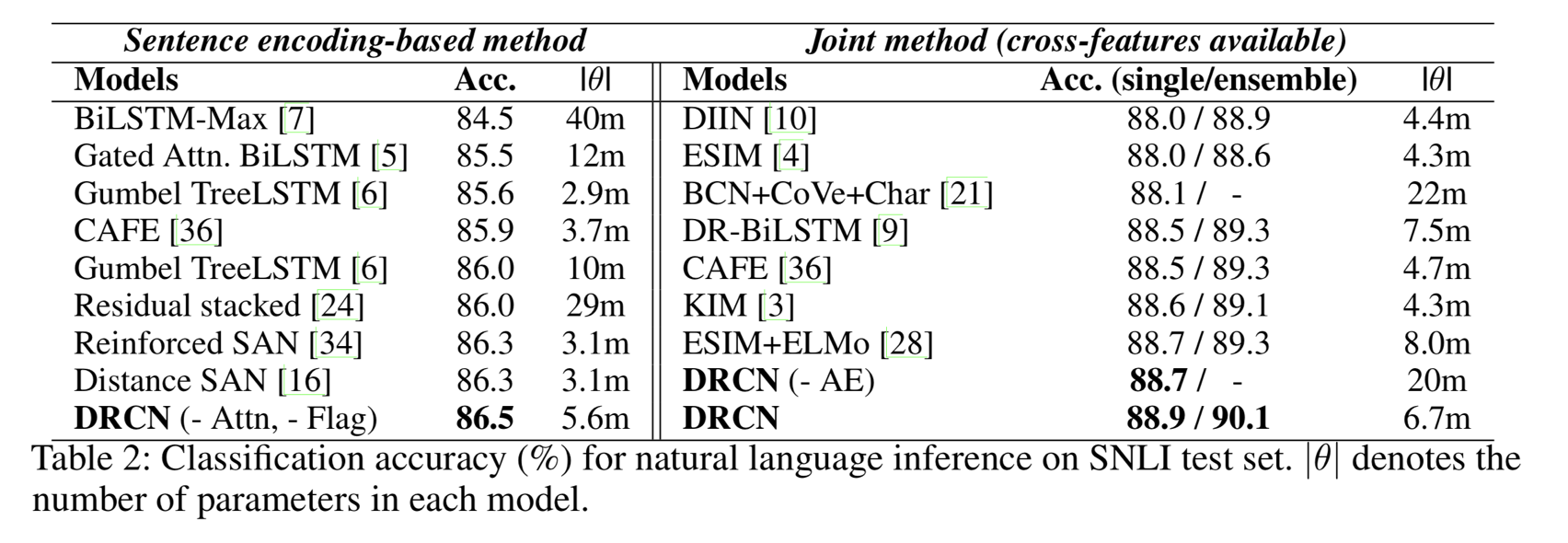
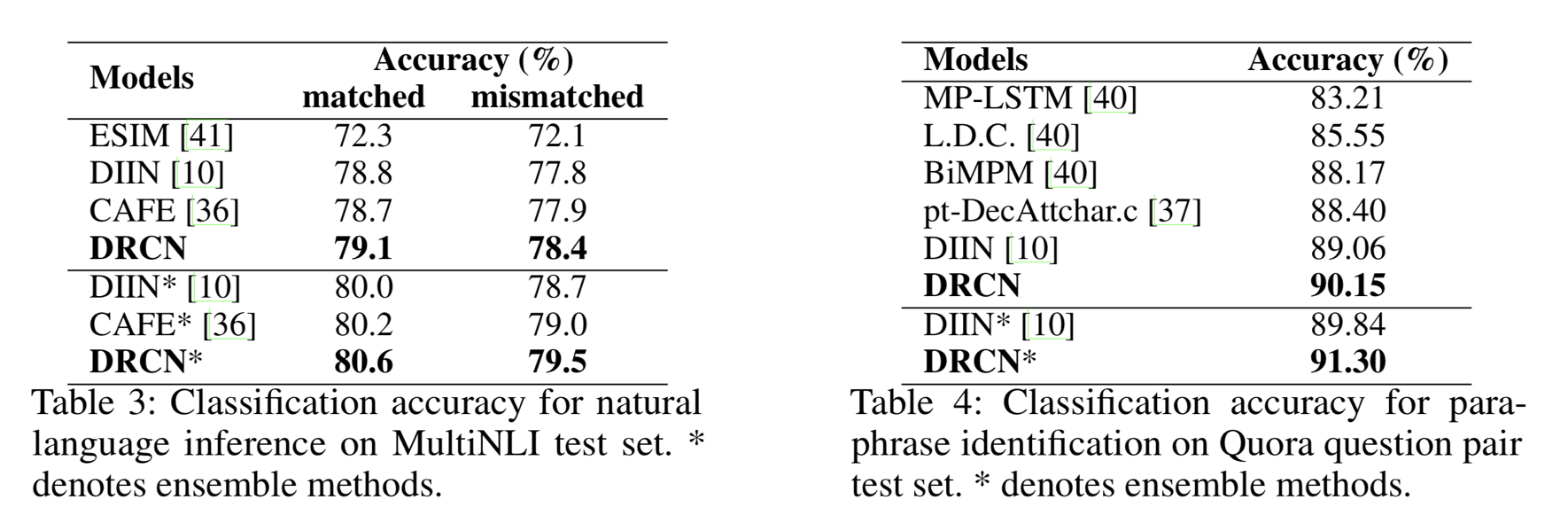
这个模型Ensemble之后的结果目前是SNLI的第一,当然BERT的效果应该是比它好,下图是在MultiNLI和Quora数据集上的结果,也算可以了,比BERT少2-3个点。
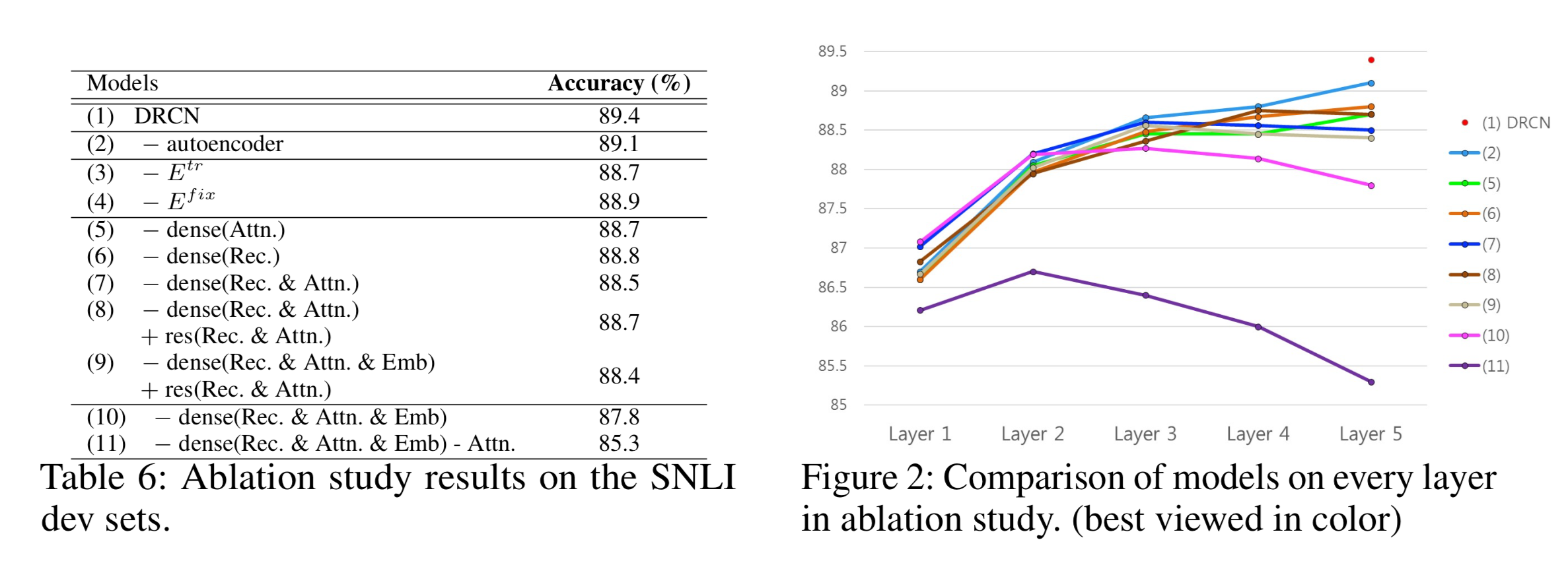
最后是在SNLI上的Ablation study,结果发现任务相关的词向量、Attention和dense-connect对模型的影响比较大。
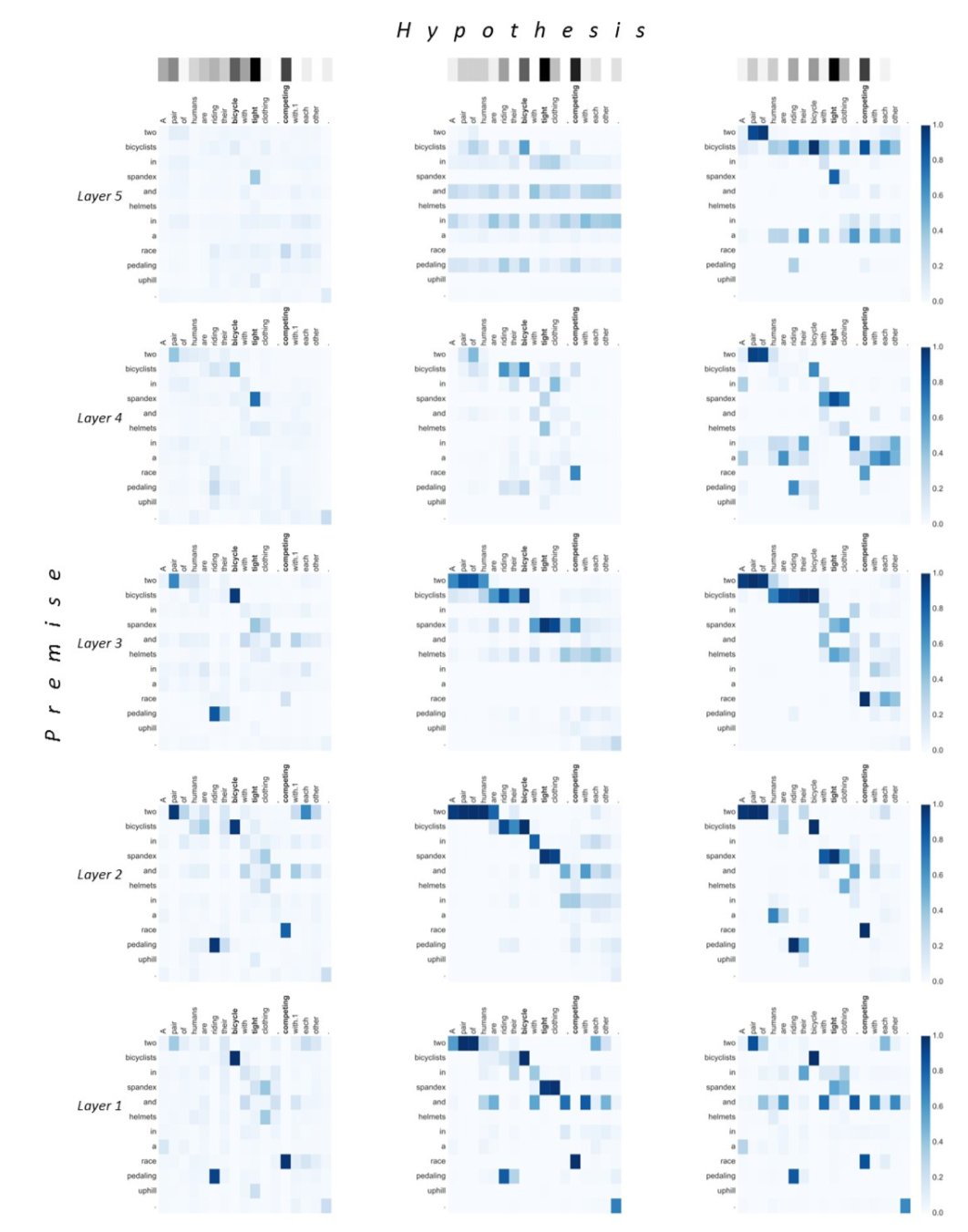
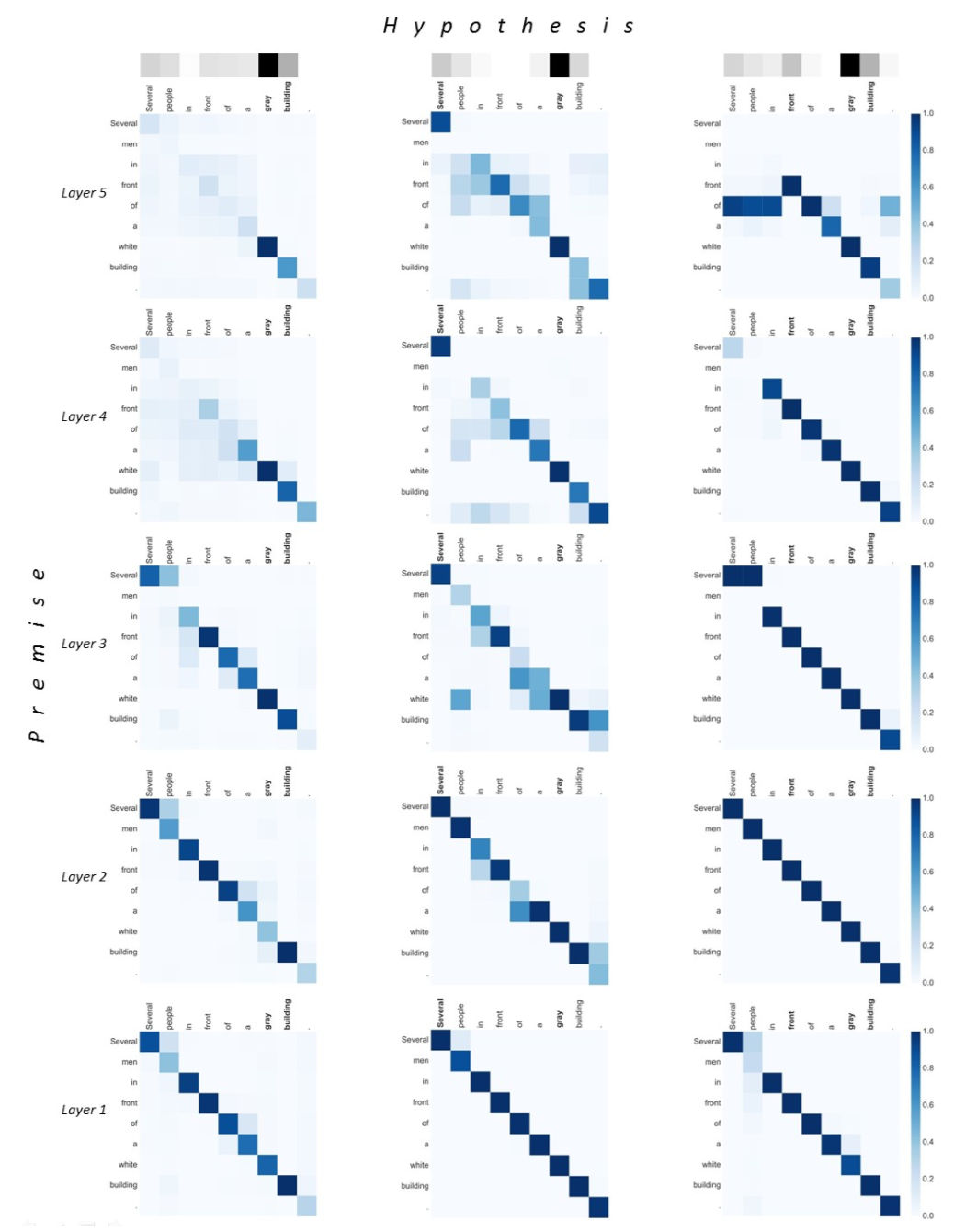
文中还最后举了两个例子,一个蕴含一个矛盾,指出DRCN五层后的找到的词比ResNet更准确,图有点长,还是放上吧。
Visualization of attentive weights on the entailment example.
The premise is “two bicyclists in spandex and helmets in a race pedaling uphill.”
The hypothesis is “A pair of humans are riding their bicycle with tight clothing, competing with each other.”
Visualization of attentive weights on the contradiction example.
The premise is “Several men in front of a white building.”
The hypothesis is “Several people in front of a gray building.”.
Conclusion
这篇文章主要集中在句子匹配任务上
- 借鉴ResNet和DenseNet,运用到stack RNN中;
- 将注意力权值作为一个特征并在h, x的中间,做法很新颖;
- 利用AutoEncoder来压缩向量,减少参数迅速增加的压力。
References
- Seonhoon Kim et al. Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information.arXiv: 1805.11360
- Yichen Gong, Heng Luo, and Jian Zhang. Natural language inference over interaction space. In International Conference on Learning Representations, 2018.
- Gao Huang, Zhuang Liu, Kilian Q Weinberger, and Laurens van der Maaten. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, volume 1, page 3, 2017.